What is Data Virtualization
What is Data Virtualization?
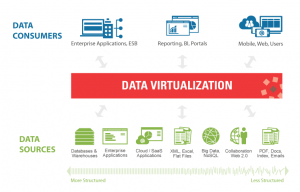
Data virtualization is a virtual layer between data sources and data consumers. In simple farm it is a mediator between various data sources and data consumers. It delivers a simplified, unified, and integrated view of trusted business data in real time or near real time as needed by the consuming applications, processes, analytics, or business users. Data virtualization integrates data from disparate sources, locations and formats, without replicating the data, to create a single “virtual” data layer that delivers unified data services to support multiple applications and users. The result is faster access to all data, less replication and cost, more agility to change.
What is Data virtualization layer does?
1. Unified data governance & security – All data is made discoverable and integratable easily through a single virtual layer which expose redundancy and quality issues faster. While they are addressed, data virtualization imposes data model governance and security from source to output data services, and consistency in integration and data quality rules.
2. Agile data services provisioning – Data virtualization promotes the API economy. Any primary, derived, integrated or virtual data source can be made accessible in a different format or protocol than the original, with controlled access in a matter of minutes.
3. Logical abstraction and decoupling – Disparate data sources, middleware, and consuming applications that use or expect specific platforms and interfaces, formats, schema, security protocols, query paradigms and other idiosyncrasies can now interact easily through data virtualization.
4. Data federation – Data federation is a subset of data virtualization, but now enhanced with more intelligent real-time query optimization, caching, in-memory and hybrid strategies that are automatically (or manually) chosen based on source constraints, application need, network awareness.
5. Semantic integration of structured & unstructured – Data virtualization is one of the few technologies that bridge the semantic understanding of unstructured and web data with the schema-based understanding of structured data to enable integration and data quality improvements.
How does Data Virtualization Architecture Looks like?
Data Virtualization Platfarms available
Actifio Copy Data Virtualization
Capsenta’s Ultrawrap Platform [9]
Cisco Data Virtualization (formerly Composite Software)
Delphix Data Virtualization Platform
Denodo Platform
DataVirtuality
Data Virtualization Platform
HiperFabric Data Virtualization and Integration
Querona [10]
Stone Bond Technologies Enterprise Enabler Data Virtualization Platform – http://www.stonebond.com
Red Hat JBoss Enterprise Application Platform Data Virtualization
Veritas Provisioning File System / Data Virtualization Veritas_Technologies
XAware Data Services
Let us not confuse with virtualization and functionalities with the following.
1. Data Visualization is different from data virtualization – Though looks similar these two are very different. Data visualization is used to view the data from the Data virtualization layer.
2. Data Virtualization is not a data store – This layer will not replicate or duplicate the source data. Rather data virtualization layer stores only meta data from the data sources.
In Upcoming discussions I am planning setup the lab at home and try the Redhat Virtualization and Denodo Platform. Will keep you all updated here